Method

3D human avatars are represented as neural implicit surfaces \(\mathcal{S}\) - specifically as the zero-level-sets of signed distance fields (SDFs).
We predict a distribution over 3D human surfaces \(p_\Theta (\mathcal{S} | \mathbf{I})\) conditioned on an input image \(\mathbf{I}\)
using a denoising diffusion probabilistic model.
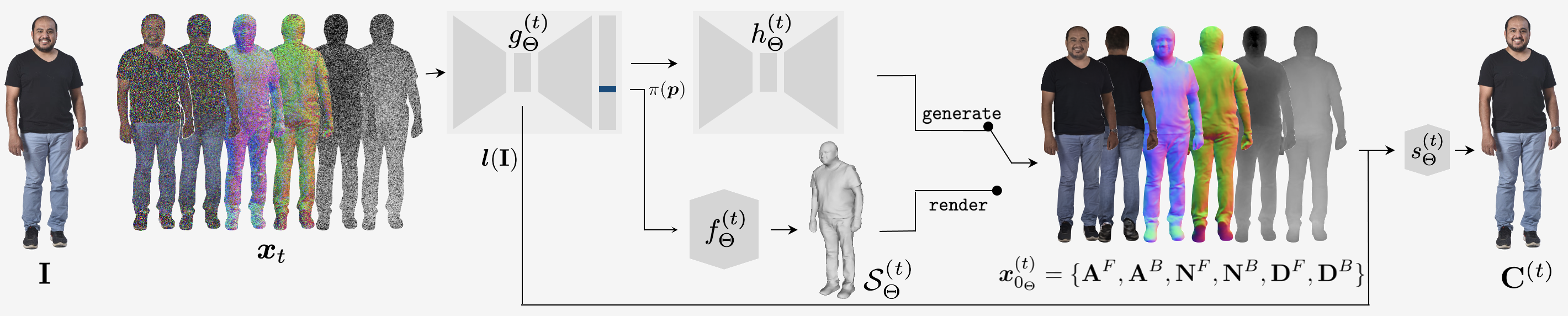
In practice, we model a distribution over image-based pixel-aligned observations of the surface \(\mathcal{S}\).
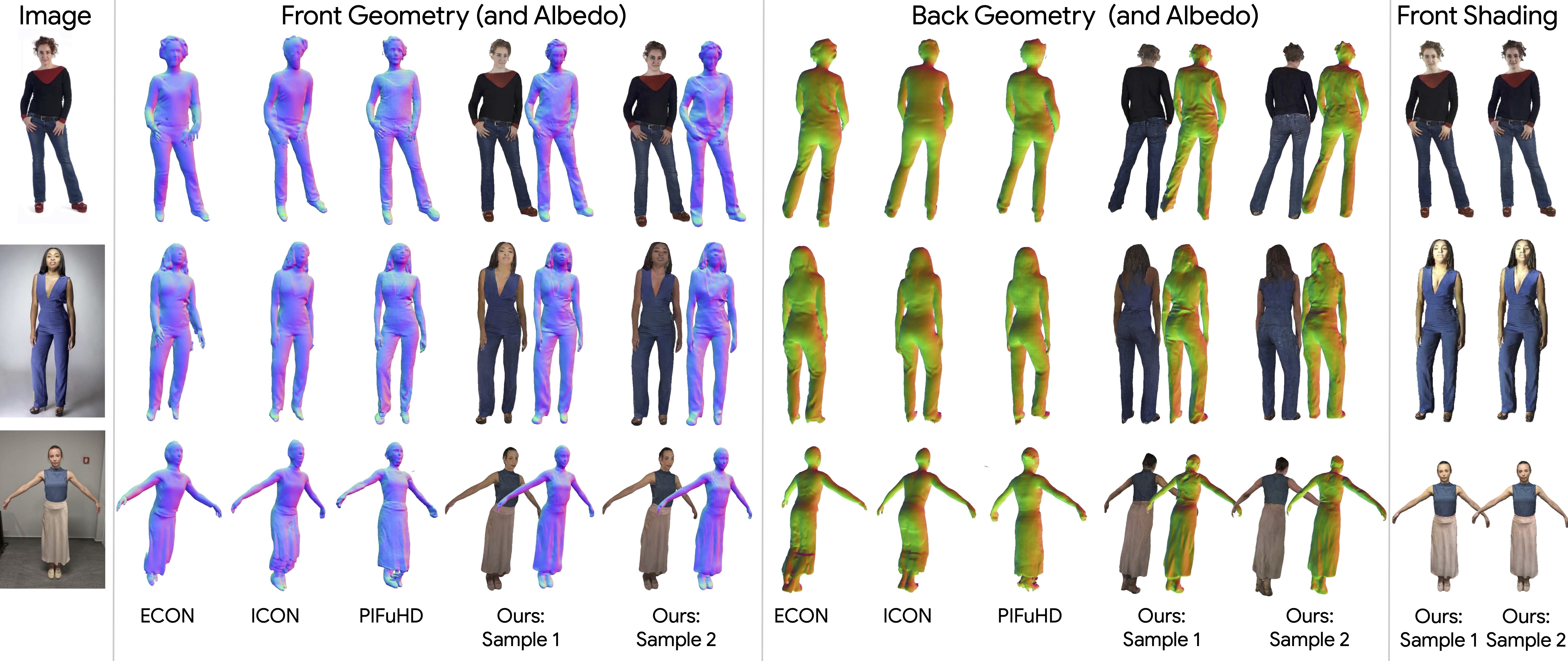
Front and back albedo images, surface normal images and depth maps comprise an "observation set" \(\boldsymbol{x}_0 = \{\mathbf{A}^F, \mathbf{A}^B, \mathbf{N}^F, \mathbf{N}^B, \mathbf{D}^F, \mathbf{D}^B \}\).
Since \(\boldsymbol{x}_0\) is effectively a multichannel image, we can borrow architectural components and methods from conventional image-based diffusion models.
Our denoising diffusion model outputs a prediction of the “clean” observation set \(\boldsymbol{x}_{0_\Theta}^{(t)}\) given a noisy version \(\boldsymbol{x}_t\).
An underlying surface \(\mathcal{S}_\Theta^{(t)}\) is estimated as an intermediate 3D representation in each denoising step, given by the zero-level-set of an SDF \(f_\Theta^{(t)}\) conditioned on pixel-aligned features \(g_\Theta^{(t)} (\boldsymbol{x}_t, \mathbf{I})\).
\(f^{(t)}_\Theta\) and \(g^{(t)}_\Theta\) are both neural networks.
\(\boldsymbol{x}_{0_\Theta}^{(t)}\) is obtained by rendering \(\mathcal{S}_\Theta^{(t)}\).
During inference, we can sample trajectories over observation sets \(\boldsymbol{x}_{0:T} \sim p_\Theta(\boldsymbol{x}_{0:T} | \mathbf{I})\) by computing and rendering \(\mathcal{S}_\Theta^{(t)}\) in each denoising step.
The final implicit surface \(\mathcal{S} = \mathcal{S}_\Theta^{(1)}(\boldsymbol{x}_1, \mathbf I)\) represents a 3D reconstruction sample \(\mathcal{S} \sim p_\Theta(\mathcal{S}| \mathbf{I})\).

However, computing and rendering a neural implicit surface in every denoising step is very computationally expensive.
To alleviate this, we additionally train a "generator" neural network \(h_\Theta^{(t)}\) that directly maps features \(g_\Theta^{(t)} (\boldsymbol{x}_t, \mathbf{I})\) to \(\boldsymbol{x}_{0_\Theta}^{(t)}\) with an image-to-image architecture.
During inference, we denoise using \(h_\Theta^{(t)}\), and only explicitly compute a 3D surface in the final denoising step.
This results in a 55x speed-up over rendering in every step.